Die Wahl des geeigneten Machine Learning Systems für ein Problem
Bevor Machine Learning zum Einsatz kommt, sollte man sich zunächst fragen, welche Art von Problem es damit zu lösen gilt. Da es sehr viele verschiedene Ausprägungen von maschinellen Lernsystemen gibt, ist es sinnvoll sie nach den folgenden Kriterien in größere Kategorien einzuteilen:
Je nachdem, ob eine Person in den Lernprozess eingreifen soll, fällt die Entscheidung auf einen supervised, unsupervised, semi-supervised oder reinforcement learning Ansatz.
Muss das Systemmodell schrittweise oder im laufenden Betrieb lernen (online vs. batch)?
Reicht es aus, neue Datenpunkte einfach mit bekannten Datenpunkten zu vergleichen oder ist es stattdessen notwendig Muster in den Trainingsdaten zu erkennen und ein vorhersagefähiges Modell zu erstellen (instanzbasiertes vs. modellbasiertes Training).
Eine der häufigsten Aufgaben für Supervised Learning ist die Klassifizierung, wie sie im Beispiel des Spamfilters zum Einsatz kommt. Dieser lernt fortlaufend indem er beispielsweise ein tiefgreifendes neuronales Netzwerk nutzt, welches anhand von Beispielen trainiert wird. Es handelt sich somit um ein online, modellbasiertes, supervised learning System. Dem Spamfilter wird mit vielen Beispiel-E-Mails und den zugehörigen Klassen antrainiert, ob es sich dabei um Spam oder Ham handelt. Das Modell des Spamfilters lernt dadurch, wie neue E-Mails zu klassifizieren sind.
Eine weitere typische Aufgabe für Supervised Learning Modelle besteht darin, konkrete Zahlenwerte zu prognostizieren, wie beispielsweise den Preis eines bestimmten Objekts. Diese Prognose kann im Rahmen einer sogenannten Regression durch die Angabe einer Reihe von Eigenschaften erfolgen, welche auch als Predictors bezeichnet werden. Bei einer Prognose für Autopreise könnten also folgende Eigenschaften im Lernmodell berücksichtigt werden: Kilometerstand, Alter, Marke, Jahresmodell. Die Quantität und Qualität der Trainingsdaten haben meistens weitaus mehr Einfluss auf die Genauigkeit des Modells als die Auswahl und das Tuning des Algorithmus. Daher werden ausreichend viele Beispiele für die Wunschobjekte (z.B. Autos) mit ihren Predictors und den zugehörigen Labels benötigt, um das System gut trainieren zu können.
Der Supervised Learning Workflow
Die folgende Grafik beschreibt den Prozess des überwachten Lernens in der Praxis.
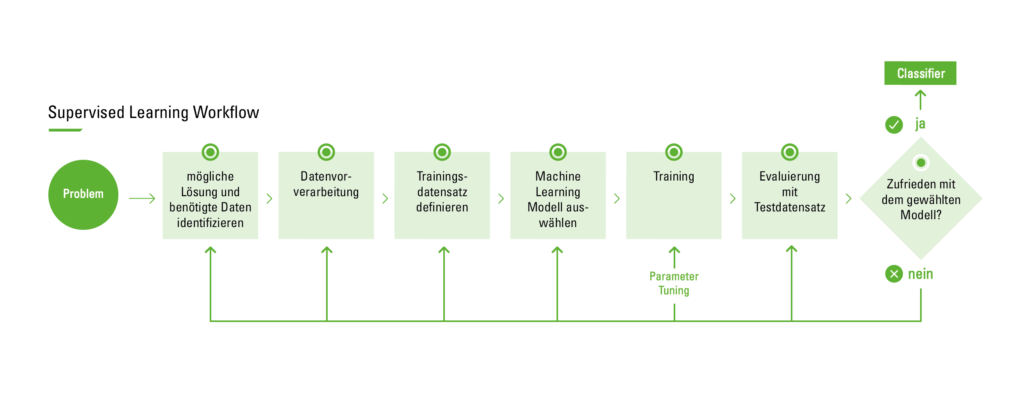
Supervised Learning Workflow
Vor Beginn des Prozesses gilt es zunächst das Problem zu identifizieren, um mit einem geeigneten Lösungsansatz fortfahren zu können. Anschließend beginnt man mit dem Sammeln des Datensatzes. Dabei wird womöglich der Rat eines Experten benötigt. Dieser soll bewerten, welche Parameter den größten Einfluss auf den Output haben und somit am relevantesten sind. Nicht für alle Fälle wird es jedoch gelingen einen entsprechenden Experten zu finden, um bei der Analyse der zu importierenden Eigenschaften zu unterstützen. In diesem Fall greift man am einfachsten auf die sogenannte Brute Force Methode zurück. In diesem Zusammenhang bedeutet es, alle vorhandenen Daten zu analysieren, in der Hoffnung die richtigen und relevanten Eigenschaften isolieren zu können. Ein mit dieser Methode erhobener Datensatz muss jedoch gereinigt und vorverarbeitet werden, da er oftmals Rauschen enthält oder Eigenschaftswerte fehlen. Unter Rauschen versteht man extreme Ausreißer-Werte, die nicht in dem Bereich der Durchschnittsfälle liegen und somit die Ergebnisse des Algorithmus verfälschen können.
Der zweite Schritt ist die Datenaufbereitung und Datenvorverarbeitung. Für die Verarbeitung fehlender Daten aus dem Datensatz können verschiedene Methoden angewandt werden, wie zum Beispiel die Instance selection. Sie wird verwendet, um mit Rauschen in Daten zu umgehen und der Schwierigkeit zu begegnen aus sehr großen Datensätzen zu lernen, indem es dabei unterstützt, irrelevante Daten zu entfernen. Die Tatsache, dass viele Eigenschaften voneinander abhängen, beeinflusst oft die Genauigkeit der Supervised Learning Klassifikationsmodelle. Dieses Problem kann durch die Entwicklung neuer Features aus dem Basis-Funktionsumfang behoben werden. Diese Vorgehensweise wird als feature construction / transformation bezeichnet. Die neu generierten Eigenschaften können zur Erstellung präziserer und genauerer Classifier führen. Als Beispiel kann man sich eine Liste von Personen vorstellen, bei denen es einzelne Personen gibt, die ihr Gewicht nicht angegeben haben. Um diese Personen trotzdem mit einbeziehen zu können, kann man z.B. einfach den Durchschnitt aller Gewichte nehmen und es ihnen zuweisen. Darüber hinaus trägt die Entdeckung sinnvoller Eigenschaften zu einer besseren Verständlichkeit des erzeugten Classifiers und einem besseren Verständnis des erlernten Konzepts bei.
Im nächsten Schritt erfolgt die Auswahl des benötigten Lernalgorithmus. Dieser Schritt ist der kritischste. Sobald das Modell mit den zuvor erstellten Testdatensätzen getestet wurde und das Ergebnis zufriedenstellend ist, ist der Classifier bereit für die abschließende Evaluierung vor dem routinemäßigen Einsatz. Die Bewertung kann beispielsweise auf der Vorhersagegenauigkeit basieren, also dem Prozentsatz der korrekten Prognose dividiert durch die Gesamtzahl der Prognosen. Zur Berechnung der Genauigkeit können folgende Vorgehensweisen verwendet werden:
Eine Herangehensweise ist die Aufteilung des Trainingsdatensatzes, wobei zwei Drittel für das Training genutzt werden. Das andere Drittel wird für das Test-Set verwendet, bei welchem man versucht zu erkennen, wie gut der Algorithmus bei noch nicht bekannten Eingaben abschneidet.
Eine weitere bekannte Technik ist die Kreuzvalidierung. Dabei wird der Trainingsdatensatz in sich gegenseitig ausschließende, gleich große Teilmengen unterteilt und für jede Teilmenge wird der Classifier auf die Gesamtheit aller anderen Teilmengen trainiert. Der Mittelwert der Fehlerrate jeder Teilmenge ist daher eine Schätzung der Fehlerrate des Classifiers.
Wird nach der Bewertung des Modells festgestellt, dass die Fehlerquote unbefriedigend ist, muss zur vorherigen Phase des Supervised Learning Workflows zurückgekehrt werden. Es gilt dann verschiedene Faktoren zu untersuchen: Werden nicht relevante Eigenschaften für das Problem verwendet? Wird ein größerer Trainingssatz benötigt? Ist die Dimensionalität des Problems zu hoch (Werden zu viele Attribute verwendet)? Ist der gewählte Algorithmus ungeeignet? Bedarf es einer Anpassung der Parameter? Oder ist vielleicht der Datensatz unausgewogen?
Wie lässt sich der beschriebene Workflow auf ein reales Problem anwenden?
Use Case für Supervised Learning
Für diesen Use Case wird das Problem im ersten Schritt definiert als die Prognose eines Projekt Forecasts. Als nächstes gilt es mit dem Sammeln des Datensatzes zu beginnen. Dazu werden frühere interne Projektprognosen gesammelt, welche im digatus eigenen Projektmanagement-Tool bereits vorhanden sind, da die Projektmanager an dieser Stelle sämtliche relevanten Projektinformationen dokumentieren. Darüber hinaus müssen die notwendigen, für die Prognose relevanten, Eigenschaften extrahiert und der Datensatz vorbereitet werden. Für diesen Schritt empfiehlt es sich die erfahrenen Projektmanager hinzuzuziehen, um zu erfahren, welche die wichtigsten Attribute des Datensatzes sind, um diese an das Trainingsmodell weiterzugeben (z.B. Anzahl der Mitarbeiter, Stundensätze, Feiertage, Urlaubsmuster der Mitarbeiter aus den Vorjahren, etc.). Darauf folgt ein besonders kritischer Schritt, nämlich die Auswahl des Machine Learning Modells. Es stehen mehrere Modelle zur Verfügung, aus denen man wählen kann. Einige Beispiele für die am weitesten verbreiteten Modelle im Supervised Learning:
1) Support Vector Machines
2) Linear regression
3) Logistic regression
4) naive Bayes
5) decision trees
6) Random Forest
7) k-nearest neighbour algorithm
8) Neural Networks (Multilayer perceptron)
Für diesen Use Case wird der Random Forest Ansatz gewählt. Es handelt sich dabei um eine Zusammensetzung von Entscheidungsbäumen, welches sowohl Regressions- als auch Klassifizierungsprobleme mit großen Datensätzen lösen kann. Es hilft auch dabei, die wichtigsten Variablen aus Tausenden von Eingangsvariablen zu identifizieren. Random Forest ist hochgradig skalierbar für eine beliebige Anzahl von Dimensionen und erbringt durchaus akzeptable Leistungen. Schließlich gibt es noch genetic algorithms, die sich ausgesprochen gut in jede Dimension und alle Daten mit minimaler Kenntnis der Daten selbst skalieren lassen, wobei die minimalste und einfachste Implementierung der microbial genetic algorithm ist. Mit Random Forest kann das Lernen jedoch langsam sein (abhängig von der Parametrisierung) und es ist nicht möglich, die generierten Modelle iterativ zu verbessern.
Nun ist es an der Zeit, den Datensatz auf das ausgewählte Modell zu trainieren. Im Anschluss an das Training folgt die Testphase. Anhand des Testergebnisses lässt sich feststellen, ob das Ergebnis akzeptabel ist oder die Parameter weiter angepasst werden müssen, um eine bessere Genauigkeit und ein besseres Ergebnis zu erzielen. Eventuell muss auch ein anderes Machine Learning Modell ausgewählt werden.

